Effective War Room Management: A Guide to Incident Response
· 6 min read


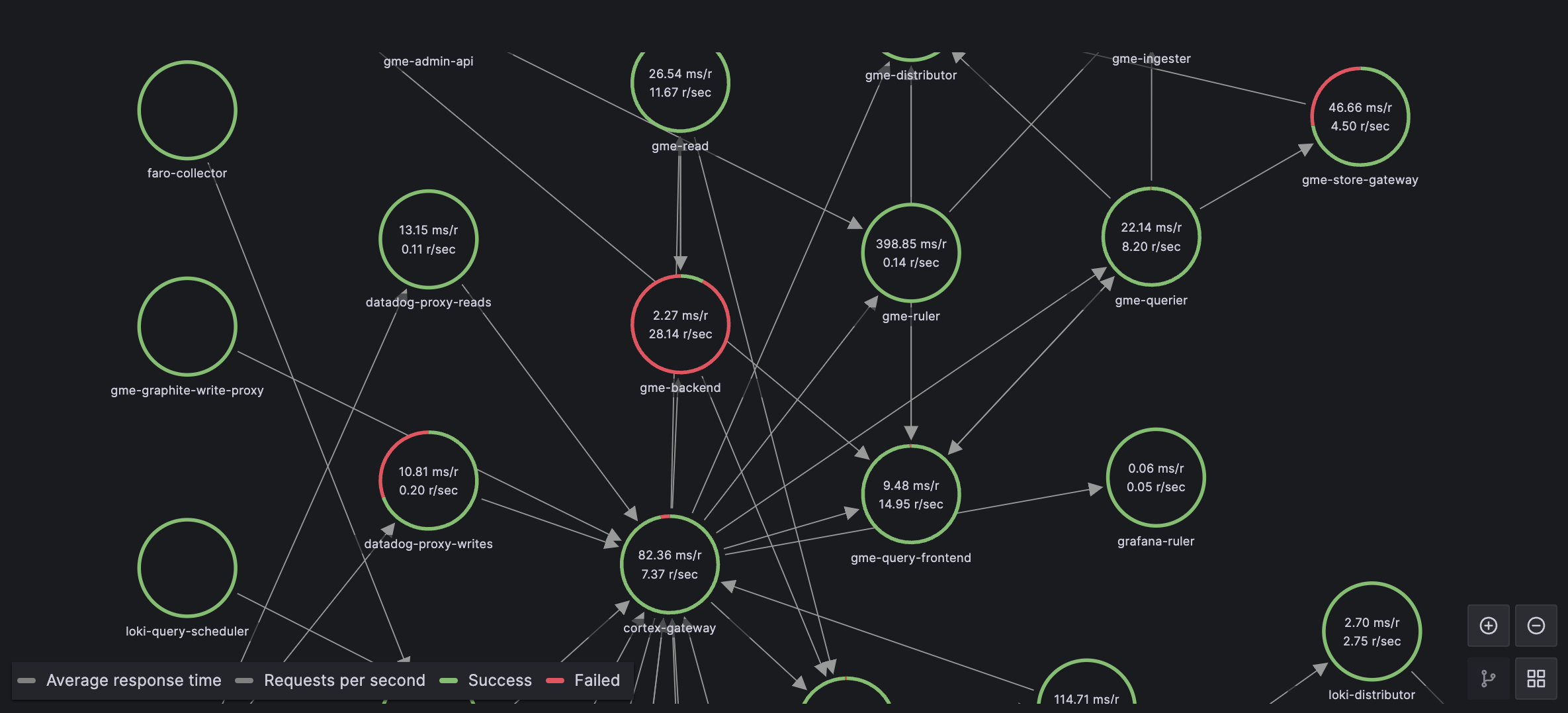
Incidents are inevitable. What separates resilient organizations from the rest is not whether they experience incidents, but how effectively they respond when problems arise. A well-structured war room process can mean the difference between a minor disruption and a major crisis.
After managing hundreds of critical incidents across my career, I've distilled my key learnings into this guide. These battle-tested practices have repeatedly proven their value in high-pressure situations.