Introducing pgX: Bridging the Gap Between Database and Application Monitoring for PostgreSQL
Watch: Tracing a slow query from application latency to PostgreSQL stats with pgX.
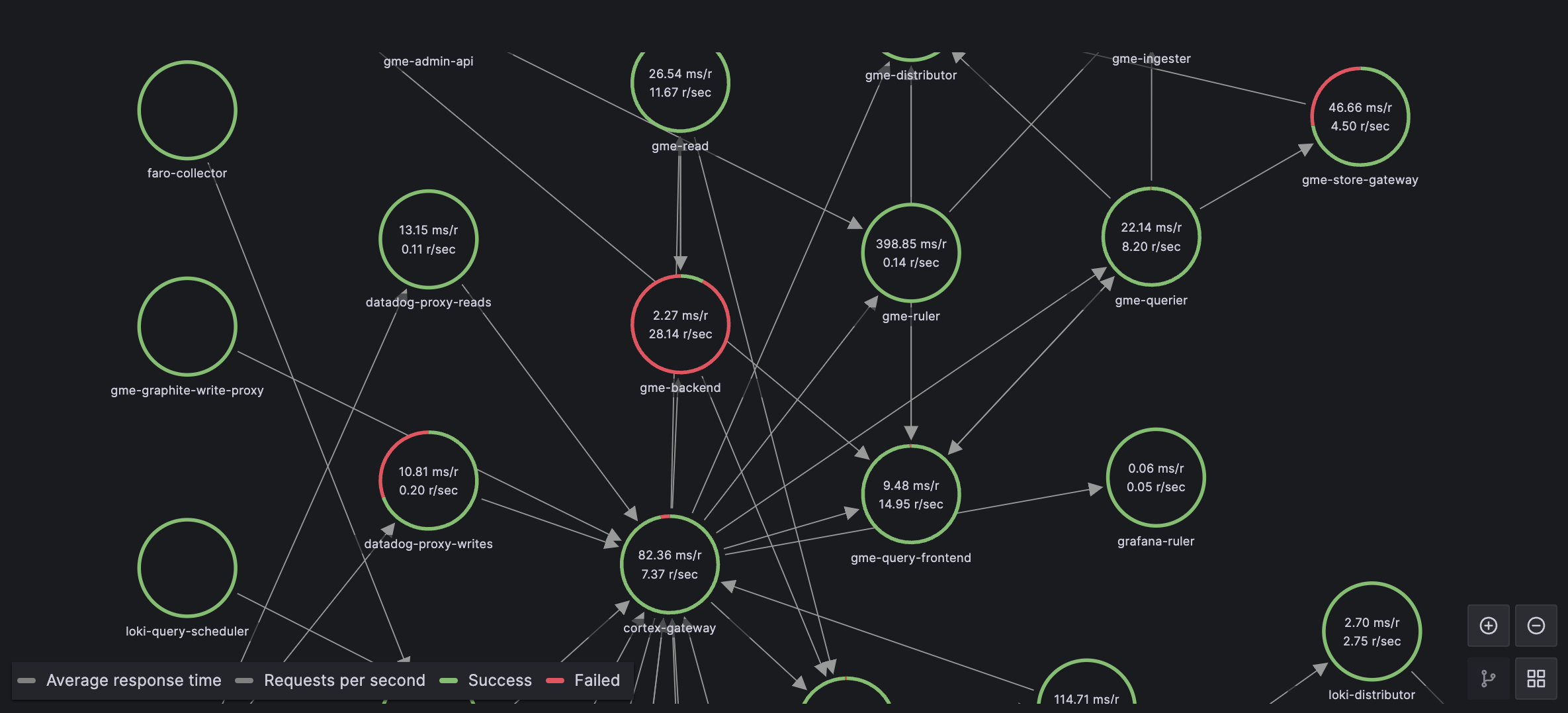
Modern software systems do not fail along clean architectural boundaries. Application latency, database contention, infrastructure saturation, and user behavior are tightly coupled, yet most observability setups continue to treat them as separate concerns, creating silos between database monitoring and APM tools. PostgreSQL, despite being a core component in most production systems, is often monitored in isolation—through a separate tool, separate dashboards, and separate mental models.
This separation works when systems are small and traffic patterns are simple. As systems scale, however, PostgreSQL behavior becomes a direct function of application usage: query patterns change with features, load fluctuates with users, and database pressure reflects upstream design decisions. At this stage, isolating database monitoring from application and infrastructure observability actively slows down diagnosis and leads teams to optimize the wrong layer.
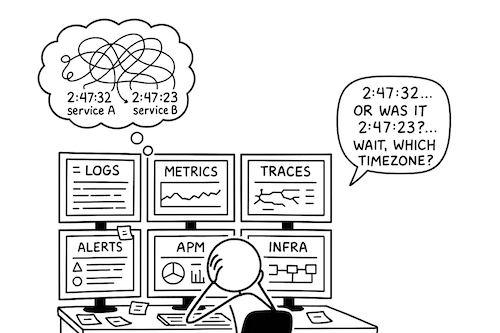
In-depth PostgreSQL monitoring is necessary—but depth alone is not sufficient. Metrics without context force engineers to manually correlate symptoms across tools, timelines, and data models. What is required instead is component-level observability—a unified database observability platform where PostgreSQL metrics live alongside application traces, infrastructure signals, and deployment events, sharing the same time axis and the same analytical surface.
This is why PostgreSQL observability belongs in the same place as application and infrastructure observability. When database behavior is observed as part of the system rather than as a standalone dependency, engineers can reason about causality instead of coincidence, and leaders gain confidence that performance issues are being addressed at their source-not just mitigated downstream.